


Churn#
1raise SystemExit("Stop right there!");
An exception has occurred, use %tb to see the full traceback.
SystemExit: Stop right there!
Importing libraries and packages#
1# System
2import os
3
4# Mathematical operations and data manipulation
5import pandas as pd
6
7# Modelling
8from keras.models import Sequential
9from keras.layers import Dense
10from sklearn.model_selection import train_test_split
11from sklearn.preprocessing import StandardScaler
12
13# Metrics
14from sklearn.metrics import confusion_matrix
15from sklearn.metrics import roc_auc_score
16from sklearn.metrics import roc_curve
17
18# Plotting
19import seaborn as sns
20import matplotlib.pyplot as plt
21
22%matplotlib inline
23
24# Suppress
25# 0 = all messages are logged (default behavior)
26# 1 = INFO messages are not printed
27# 2 = INFO and WARNING messages are not printed
28# 3 = INFO, WARNING, and ERROR messages are not printed
29os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
Set paths#
1# Path to datasets directory
2data_path = "./datasets"
3# Path to assets directory (for saving results to)
4assets_path = "./assets"
Loading dataset#
1churn_data = pd.read_csv(
2 f"{data_path}/Churn_Modelling.csv", index_col="RowNumber"
3)
4# Print first 5 rows
5churn_data.head()
| CustomerId | Surname | CreditScore | Geography | Gender | Age | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Exited | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RowNumber | |||||||||||||
| 1 | 15634602 | Hargrave | 619 | France | Female | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 2 | 15647311 | Hill | 608 | Spain | Female | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
| 3 | 15619304 | Onio | 502 | France | Female | 42 | 8 | 159660.80 | 3 | 1 | 0 | 113931.57 | 1 |
| 4 | 15701354 | Boni | 699 | France | Female | 39 | 1 | 0.00 | 2 | 0 | 0 | 93826.63 | 0 |
| 5 | 15737888 | Mitchell | 850 | Spain | Female | 43 | 2 | 125510.82 | 1 | 1 | 1 | 79084.10 | 0 |
Data wrangling#
1# Print information about the dataframe including the index
2# dtype and columns, non-null values and memory usage
3churn_data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 10000 entries, 1 to 10000
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CustomerId 10000 non-null int64
1 Surname 10000 non-null object
2 CreditScore 10000 non-null int64
3 Geography 10000 non-null object
4 Gender 10000 non-null object
5 Age 10000 non-null int64
6 Tenure 10000 non-null int64
7 Balance 10000 non-null float64
8 NumOfProducts 10000 non-null int64
9 HasCrCard 10000 non-null int64
10 IsActiveMember 10000 non-null int64
11 EstimatedSalary 10000 non-null float64
12 Exited 10000 non-null int64
dtypes: float64(2), int64(8), object(3)
memory usage: 1.1+ MB
1# Summarize the central tendency, dispersion and shape of a d
2# ataset’s distribution, excluding NaN values. This is a numeric:
3# count = number of non-NA/null observations.
4# mean = mean of the values.
5# std = standard deviation of the observations.
6# min = minimum of the values in the object.
7# lower (25), 50 and upper (75) percentiles. The 50 percentile is the
8# same as the median.
9# max = maximum of the values in the object.
10
11churn_data.describe()
| CustomerId | CreditScore | Age | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Exited | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 1.000000e+04 | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 | 10000.00000 | 10000.000000 | 10000.000000 | 10000.000000 |
| mean | 1.569094e+07 | 650.528800 | 38.921800 | 5.012800 | 76485.889288 | 1.530200 | 0.70550 | 0.515100 | 100090.239881 | 0.203700 |
| std | 7.193619e+04 | 96.653299 | 10.487806 | 2.892174 | 62397.405202 | 0.581654 | 0.45584 | 0.499797 | 57510.492818 | 0.402769 |
| min | 1.556570e+07 | 350.000000 | 18.000000 | 0.000000 | 0.000000 | 1.000000 | 0.00000 | 0.000000 | 11.580000 | 0.000000 |
| 25% | 1.562853e+07 | 584.000000 | 32.000000 | 3.000000 | 0.000000 | 1.000000 | 0.00000 | 0.000000 | 51002.110000 | 0.000000 |
| 50% | 1.569074e+07 | 652.000000 | 37.000000 | 5.000000 | 97198.540000 | 1.000000 | 1.00000 | 1.000000 | 100193.915000 | 0.000000 |
| 75% | 1.575323e+07 | 718.000000 | 44.000000 | 7.000000 | 127644.240000 | 2.000000 | 1.00000 | 1.000000 | 149388.247500 | 0.000000 |
| max | 1.581569e+07 | 850.000000 | 92.000000 | 10.000000 | 250898.090000 | 4.000000 | 1.00000 | 1.000000 | 199992.480000 | 1.000000 |
1# Remove for the purpose unproductive columns
2churn_data.drop(["CustomerId", "Surname"], axis=1, inplace=True)
1# Two columns are left which have text data: Geography and Gender.
2# Many machine learning algorithms cannot operate on text data directly.
3# They require all input variables and output variables to be numeric.
4# This means that categorical data must be converted to numerical:
5# 1. Assign each unique category value an integer value, called
6# Ordinal Encoding (or Label Encoding or Integer Encoding).
7# 2. For categorical variables where no ordinal relationship exists,
8# such as for Geography, use One-Hot Encoding.
9# https://machinelearningmastery.com/one-hot-encoding-for-categorical-data/
10# https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.get_dummies.html
11
12Geography_dummies = pd.get_dummies(
13 prefix="Geo", data=churn_data, columns=["Geography"]
14)
15Geography_dummies.head()
| CreditScore | Gender | Age | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Exited | Geo_France | Geo_Germany | Geo_Spain | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RowNumber | |||||||||||||
| 1 | 619 | Female | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 | 1 | 0 | 0 |
| 2 | 608 | Female | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 | 0 | 0 | 1 |
| 3 | 502 | Female | 42 | 8 | 159660.80 | 3 | 1 | 0 | 113931.57 | 1 | 1 | 0 | 0 |
| 4 | 699 | Female | 39 | 1 | 0.00 | 2 | 0 | 0 | 93826.63 | 0 | 1 | 0 | 0 |
| 5 | 850 | Female | 43 | 2 | 125510.82 | 1 | 1 | 1 | 79084.10 | 0 | 0 | 0 | 1 |
1# For Gender, ordinal encoding can be used
2Gender_dummies = Geography_dummies.replace(
3 to_replace={"Gender": {"Female": 1, "Male": 0}}
4)
5Gender_dummies.head()
| CreditScore | Gender | Age | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Exited | Geo_France | Geo_Germany | Geo_Spain | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RowNumber | |||||||||||||
| 1 | 619 | 1 | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 | 1 | 0 | 0 |
| 2 | 608 | 1 | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 | 0 | 0 | 1 |
| 3 | 502 | 1 | 42 | 8 | 159660.80 | 3 | 1 | 0 | 113931.57 | 1 | 1 | 0 | 0 |
| 4 | 699 | 1 | 39 | 1 | 0.00 | 2 | 0 | 0 | 93826.63 | 0 | 1 | 0 | 0 |
| 5 | 850 | 1 | 43 | 2 | 125510.82 | 1 | 1 | 1 | 79084.10 | 0 | 0 | 0 | 1 |
1# Put the results in a new churn_data dataframe, and check results
2churn_data_encoded = Gender_dummies
3churn_data_encoded
| CreditScore | Gender | Age | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Exited | Geo_France | Geo_Germany | Geo_Spain | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RowNumber | |||||||||||||
| 1 | 619 | 1 | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 | 1 | 0 | 0 |
| 2 | 608 | 1 | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 | 0 | 0 | 1 |
| 3 | 502 | 1 | 42 | 8 | 159660.80 | 3 | 1 | 0 | 113931.57 | 1 | 1 | 0 | 0 |
| 4 | 699 | 1 | 39 | 1 | 0.00 | 2 | 0 | 0 | 93826.63 | 0 | 1 | 0 | 0 |
| 5 | 850 | 1 | 43 | 2 | 125510.82 | 1 | 1 | 1 | 79084.10 | 0 | 0 | 0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 9996 | 771 | 0 | 39 | 5 | 0.00 | 2 | 1 | 0 | 96270.64 | 0 | 1 | 0 | 0 |
| 9997 | 516 | 0 | 35 | 10 | 57369.61 | 1 | 1 | 1 | 101699.77 | 0 | 1 | 0 | 0 |
| 9998 | 709 | 1 | 36 | 7 | 0.00 | 1 | 0 | 1 | 42085.58 | 1 | 1 | 0 | 0 |
| 9999 | 772 | 0 | 42 | 3 | 75075.31 | 2 | 1 | 0 | 92888.52 | 1 | 0 | 1 | 0 |
| 10000 | 792 | 1 | 28 | 4 | 130142.79 | 1 | 1 | 0 | 38190.78 | 0 | 1 | 0 | 0 |
10000 rows × 13 columns
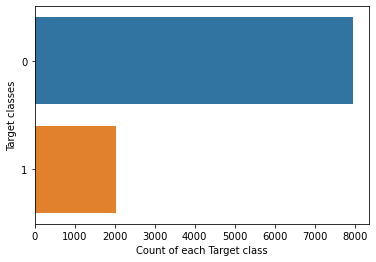
1# Show the counts of observations in each categorical bin
2# (column Exited) using bars.
3# https://seaborn.pydata.org/generated/seaborn.countplot.html
4sns.countplot(y=churn_data_encoded.Exited, data=churn_data_encoded)
5plt.xlabel("Count of each Target class")
6plt.ylabel("Target classes")
7plt.show()
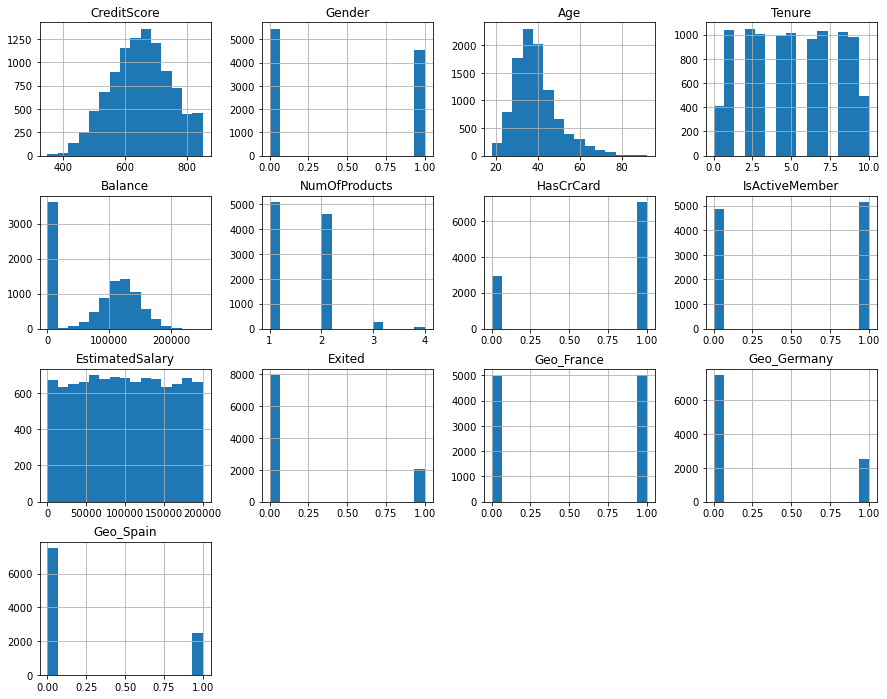
1# Show distributions of the dataset
2# https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.hist.html
3# https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.title.html
4# https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.show.html
5churn_data_encoded.hist(figsize=(15, 12), bins=15)
6plt.title("Features Distribution")
7plt.show()
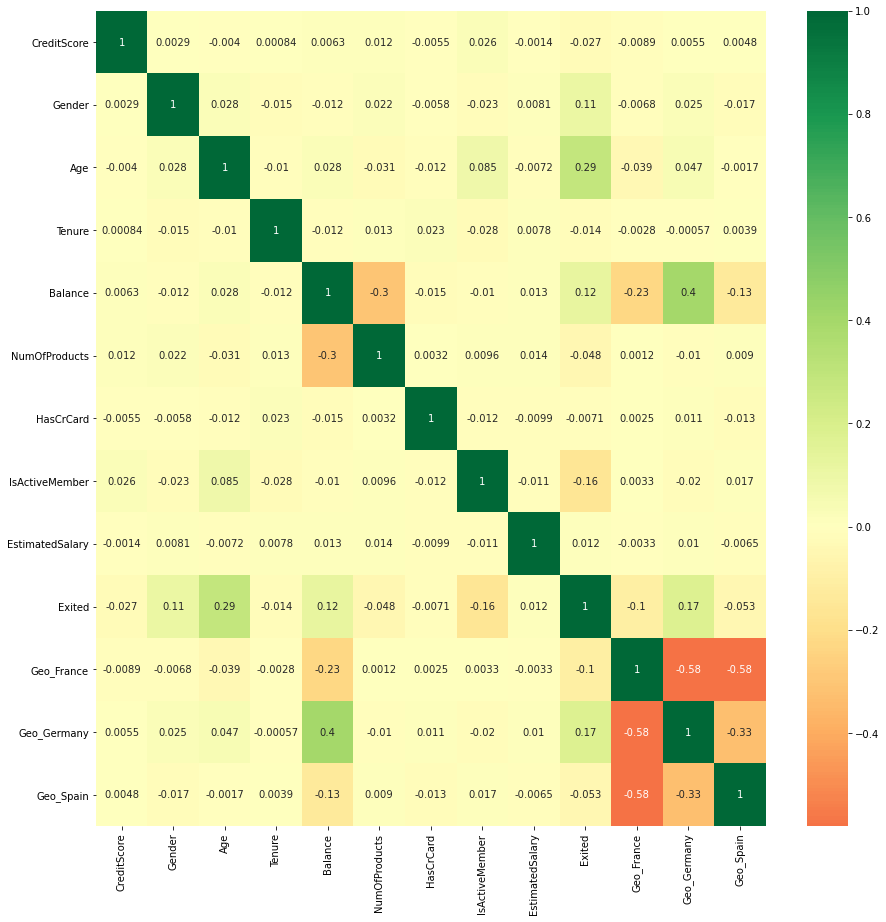
1# Plot rectangular data as a color-encoded matrix.
2# https://seaborn.pydata.org/generated/seaborn.heatmap.html#seaborn.heatmap
3# https://matplotlib.org/stable/api/figure_api.html
4plt.figure(figsize=(15, 15))
5p = sns.heatmap(churn_data_encoded.corr(), annot=True, cmap="RdYlGn", center=0)
Training of the network#
1# Exited is target class
2X = churn_data_encoded.drop(["Exited"], axis=1)
3y = churn_data_encoded.Exited
1# Check
2X.head(10)
| CreditScore | Gender | Age | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Geo_France | Geo_Germany | Geo_Spain | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RowNumber | ||||||||||||
| 1 | 619 | 1 | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 | 0 | 0 |
| 2 | 608 | 1 | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 | 0 | 1 |
| 3 | 502 | 1 | 42 | 8 | 159660.80 | 3 | 1 | 0 | 113931.57 | 1 | 0 | 0 |
| 4 | 699 | 1 | 39 | 1 | 0.00 | 2 | 0 | 0 | 93826.63 | 1 | 0 | 0 |
| 5 | 850 | 1 | 43 | 2 | 125510.82 | 1 | 1 | 1 | 79084.10 | 0 | 0 | 1 |
| 6 | 645 | 0 | 44 | 8 | 113755.78 | 2 | 1 | 0 | 149756.71 | 0 | 0 | 1 |
| 7 | 822 | 0 | 50 | 7 | 0.00 | 2 | 1 | 1 | 10062.80 | 1 | 0 | 0 |
| 8 | 376 | 1 | 29 | 4 | 115046.74 | 4 | 1 | 0 | 119346.88 | 0 | 1 | 0 |
| 9 | 501 | 0 | 44 | 4 | 142051.07 | 2 | 0 | 1 | 74940.50 | 1 | 0 | 0 |
| 10 | 684 | 0 | 27 | 2 | 134603.88 | 1 | 1 | 1 | 71725.73 | 1 | 0 | 0 |
1# Split dataset into the Training set and Test set
2# https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
3X_train, X_test, y_train, y_test = train_test_split(
4 X, y, test_size=0.33, random_state=0
5)
6
7# The dataset contains attributes with a mixtures of scales for
8# various quantities.
9# Many machine learning methods expect or are more effective if
10# the data attributes have the same scale.
11# https://machinelearningmastery.com/standardscaler-and-minmaxscaler-transforms-in-python/
12# https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html
13sc = StandardScaler()
14X_train = sc.fit_transform(X_train)
15X_test = sc.transform(X_test)
1# Sequential model to initialise our ANN and dense module to build the layers.
2# https://keras.io/guides/sequential_model/
3# https://keras.io/api/layers/core_layers/dense/
1# Create a Sequential model with 3 layers incrementally
2# https://keras.io/guides/
3
4classifier = Sequential()
5
6# Adding the input layer and the first hidden layer
7classifier.add(
8 Dense(
9 units=6, kernel_initializer="uniform", activation="relu", input_dim=12
10 )
11)
12# Adding the second hidden layer
13classifier.add(Dense(units=6, kernel_initializer="uniform", activation="relu"))
14# Adding the output layer
15classifier.add(
16 Dense(units=1, kernel_initializer="uniform", activation="sigmoid")
17)
18
19# Compiling the ANN | means applying SGD on the whole ANN
20classifier.compile(
21 optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"]
22)
23
24# Fitting the ANN to the Training set
25classifier.fit(X_train, y_train, batch_size=10, epochs=100, verbose=0)
<tensorflow.python.keras.callbacks.History at 0x7f41e8445040>
Evaluations#
1score, acc = classifier.evaluate(X_train, y_train, batch_size=10)
2print("Train score:", score)
3print("Train accuracy:", acc)
4
5# Making predictions and evaluating the model
6# Predicting the Test set results
7y_pred = classifier.predict(X_test)
8y_pred = y_pred > 0.5
9
10print("*" * 20)
11score, acc = classifier.evaluate(X_test, y_test, batch_size=10)
12print("Test score:", score)
13print("Test accuracy:", acc)
14
15# Making the Confusion Matrix
16cm = confusion_matrix(y_test, y_pred)
1# Evaluation metrics
2p = sns.heatmap(pd.DataFrame(cm), annot=True, cmap="YlGnBu", fmt="g")
3plt.title("Confusion matrix", y=1.1)
4plt.ylabel("Actual label")
5plt.xlabel("Predicted label")
1# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_curve.html
2y_pred = classifier.predict(X_test)
3fpr, tpr, thresholds = roc_curve(y_test, y_pred)
4plt.plot([0, 1], [0, 1], "k--")
5plt.plot(fpr, tpr, label="ANN")
6plt.xlabel("fpr")
7plt.ylabel("tpr")
8plt.title("ROC curve")
9plt.show()
1# Area under ROC curve
2roc_auc_score(y_test, y_pred)