

Ames Housing Model Training#
Using the transformed datasets and the selected variables saved in the previous notebooks to try a model.
Reproducibility: Setting the seed#
With the aim to ensure reproducibility between runs of the same notebook, and between the research and production environment, for each step that includes some element of randomness, it is extremely important that the seed is set.
Libraries and packages#
1# to handle datasets
2import pandas as pd
3import numpy as np
4
5# for plotting
6import matplotlib.pyplot as plt
7
8# to save the model
9import joblib
10
11# to build the model
12from sklearn.linear_model import Lasso
13
14# to evaluate the model
15from sklearn.metrics import mean_squared_error, r2_score
16
17# to visualise al the columns in the dataframe
18pd.pandas.set_option("display.max_columns", None)
Paths#
1# Path to datasets directory
2data_path = "./datasets"
3# Path to assets directory (for saving results to)
4assets_path = "./assets"
Loading dataset#
1# Load the train and test set with the engineered variables
2X_train = pd.read_csv(f"{data_path}/xtrain.csv")
3X_test = pd.read_csv(f"{data_path}/xtest.csv")
4
5X_train.head()
| MSSubClass | MSZoning | LotFrontage | LotArea | Street | Alley | LotShape | LandContour | Utilities | LotConfig | LandSlope | Neighborhood | Condition1 | Condition2 | BldgType | HouseStyle | OverallQual | OverallCond | YearBuilt | YearRemodAdd | RoofStyle | RoofMatl | Exterior1st | Exterior2nd | MasVnrType | MasVnrArea | ExterQual | ExterCond | Foundation | BsmtQual | BsmtCond | BsmtExposure | BsmtFinType1 | BsmtFinSF1 | BsmtFinType2 | BsmtFinSF2 | BsmtUnfSF | TotalBsmtSF | Heating | HeatingQC | CentralAir | Electrical | 1stFlrSF | 2ndFlrSF | LowQualFinSF | GrLivArea | BsmtFullBath | BsmtHalfBath | FullBath | HalfBath | BedroomAbvGr | KitchenAbvGr | KitchenQual | TotRmsAbvGrd | Functional | Fireplaces | FireplaceQu | GarageType | GarageYrBlt | GarageFinish | GarageCars | GarageArea | GarageQual | GarageCond | PavedDrive | WoodDeckSF | OpenPorchSF | EnclosedPorch | 3SsnPorch | ScreenPorch | PoolArea | PoolQC | Fence | MiscFeature | MiscVal | MoSold | SaleType | SaleCondition | LotFrontage_na | MasVnrArea_na | GarageYrBlt_na | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.750000 | 0.75 | 0.461171 | 0.366365 | 1.0 | 1.0 | 0.333333 | 1.000000 | 1.0 | 0.0 | 0.0 | 0.863636 | 0.4 | 1.0 | 0.75 | 0.6 | 0.777778 | 0.50 | 0.014706 | 0.049180 | 0.0 | 0.0 | 1.0 | 1.0 | 0.333333 | 0.00000 | 0.666667 | 0.5 | 1.0 | 0.666667 | 0.666667 | 0.666667 | 1.0 | 0.002835 | 0.0 | 0.0 | 0.673479 | 0.239935 | 1.0 | 1.00 | 1.0 | 1.0 | 0.559760 | 0.0 | 0.0 | 0.523250 | 0.000000 | 0.0 | 0.666667 | 0.0 | 0.375 | 0.333333 | 0.666667 | 0.416667 | 1.0 | 0.000000 | 0.0 | 0.75 | 0.018692 | 1.0 | 0.75 | 0.430183 | 0.5 | 0.5 | 1.0 | 0.116686 | 0.032907 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.00 | 1.0 | 0.0 | 0.545455 | 0.666667 | 0.75 | 0.0 | 0.0 | 0.0 |
| 1 | 0.750000 | 0.75 | 0.456066 | 0.388528 | 1.0 | 1.0 | 0.333333 | 0.333333 | 1.0 | 0.0 | 0.0 | 0.363636 | 0.4 | 1.0 | 0.75 | 0.6 | 0.444444 | 0.75 | 0.360294 | 0.049180 | 0.0 | 0.0 | 0.6 | 0.6 | 0.666667 | 0.03375 | 0.666667 | 0.5 | 0.5 | 0.333333 | 0.666667 | 0.000000 | 0.8 | 0.142807 | 0.0 | 0.0 | 0.114724 | 0.172340 | 1.0 | 1.00 | 1.0 | 1.0 | 0.434539 | 0.0 | 0.0 | 0.406196 | 0.333333 | 0.0 | 0.333333 | 0.5 | 0.375 | 0.333333 | 0.666667 | 0.250000 | 1.0 | 0.000000 | 0.0 | 0.75 | 0.457944 | 0.5 | 0.25 | 0.220028 | 0.5 | 0.5 | 1.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.75 | 1.0 | 0.0 | 0.636364 | 0.666667 | 0.75 | 0.0 | 0.0 | 0.0 |
| 2 | 0.916667 | 0.75 | 0.394699 | 0.336782 | 1.0 | 1.0 | 0.000000 | 0.333333 | 1.0 | 0.0 | 0.0 | 0.954545 | 0.4 | 1.0 | 1.00 | 0.6 | 0.888889 | 0.50 | 0.036765 | 0.098361 | 1.0 | 0.0 | 0.3 | 0.2 | 0.666667 | 0.25750 | 1.000000 | 0.5 | 1.0 | 1.000000 | 0.666667 | 0.000000 | 1.0 | 0.080794 | 0.0 | 0.0 | 0.601951 | 0.286743 | 1.0 | 1.00 | 1.0 | 1.0 | 0.627205 | 0.0 | 0.0 | 0.586296 | 0.333333 | 0.0 | 0.666667 | 0.0 | 0.250 | 0.333333 | 1.000000 | 0.333333 | 1.0 | 0.333333 | 0.8 | 0.75 | 0.046729 | 0.5 | 0.50 | 0.406206 | 0.5 | 0.5 | 1.0 | 0.228705 | 0.149909 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.00 | 1.0 | 0.0 | 0.090909 | 0.666667 | 0.75 | 0.0 | 0.0 | 0.0 |
| 3 | 0.750000 | 0.75 | 0.445002 | 0.482280 | 1.0 | 1.0 | 0.666667 | 0.666667 | 1.0 | 0.0 | 0.0 | 0.454545 | 0.4 | 1.0 | 0.75 | 0.6 | 0.666667 | 0.50 | 0.066176 | 0.163934 | 0.0 | 0.0 | 1.0 | 1.0 | 0.333333 | 0.00000 | 0.666667 | 0.5 | 1.0 | 0.666667 | 0.666667 | 1.000000 | 1.0 | 0.255670 | 0.0 | 0.0 | 0.018114 | 0.242553 | 1.0 | 1.00 | 1.0 | 1.0 | 0.566920 | 0.0 | 0.0 | 0.529943 | 0.333333 | 0.0 | 0.666667 | 0.0 | 0.375 | 0.333333 | 0.666667 | 0.250000 | 1.0 | 0.333333 | 0.4 | 0.75 | 0.084112 | 0.5 | 0.50 | 0.362482 | 0.5 | 0.5 | 1.0 | 0.469078 | 0.045704 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.00 | 1.0 | 0.0 | 0.636364 | 0.666667 | 0.75 | 1.0 | 0.0 | 0.0 |
| 4 | 0.750000 | 0.75 | 0.577658 | 0.391756 | 1.0 | 1.0 | 0.333333 | 0.333333 | 1.0 | 0.0 | 0.0 | 0.363636 | 0.4 | 1.0 | 0.75 | 0.6 | 0.555556 | 0.50 | 0.323529 | 0.737705 | 0.0 | 0.0 | 0.6 | 0.7 | 0.666667 | 0.17000 | 0.333333 | 0.5 | 0.5 | 0.333333 | 0.666667 | 0.000000 | 0.6 | 0.086818 | 0.0 | 0.0 | 0.434278 | 0.233224 | 1.0 | 0.75 | 1.0 | 1.0 | 0.549026 | 0.0 | 0.0 | 0.513216 | 0.000000 | 0.0 | 0.666667 | 0.0 | 0.375 | 0.333333 | 0.333333 | 0.416667 | 1.0 | 0.333333 | 0.8 | 0.75 | 0.411215 | 0.5 | 0.50 | 0.406206 | 0.5 | 0.5 | 1.0 | 0.000000 | 0.000000 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.00 | 1.0 | 0.0 | 0.545455 | 0.666667 | 0.75 | 0.0 | 0.0 | 0.0 |
1# load the target (remember that the target is log transformed)
2y_train = pd.read_csv(f"{data_path}/ytrain.csv")
3y_test = pd.read_csv(f"{data_path}/ytest.csv")
4
5y_train.head()
| SalePrice | |
|---|---|
| 0 | 12.211060 |
| 1 | 11.887931 |
| 2 | 12.675764 |
| 3 | 12.278393 |
| 4 | 12.103486 |
1# load the pre-selected features
2# ==============================
3
4features = pd.read_csv(f"{data_path}/selected_features.csv")
5features = features["0"].to_list()
6
7# display final feature set
8features
['MSSubClass',
'MSZoning',
'LotArea',
'LotShape',
'LandContour',
'LotConfig',
'Neighborhood',
'OverallQual',
'OverallCond',
'YearRemodAdd',
'RoofStyle',
'Exterior1st',
'ExterQual',
'Foundation',
'BsmtQual',
'BsmtExposure',
'BsmtFinType1',
'HeatingQC',
'CentralAir',
'1stFlrSF',
'2ndFlrSF',
'GrLivArea',
'BsmtFullBath',
'FullBath',
'HalfBath',
'KitchenQual',
'TotRmsAbvGrd',
'Functional',
'Fireplaces',
'FireplaceQu',
'GarageFinish',
'GarageCars',
'PavedDrive',
'WoodDeckSF',
'ScreenPorch',
'SaleCondition']
1# reduce the train and test set to the selected features
2X_train = X_train[features]
3X_test = X_test[features]
Regularised linear regression: Lasso#
*** set the seed ***
1# set up the model
2lin_model = Lasso(alpha=0.001, random_state=0)
3
4# train the model
5lin_model.fit(X_train, y_train)
Lasso(alpha=0.001, random_state=0)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Lasso(alpha=0.001, random_state=0)
1# evaluate the model:
2# ====================
3
4# The output was log transformed in the feature engineering
5# notebook.
6
7# In order to get the true performance of the Lasso, transform
8# the target and the predictions back to the original house
9# prices values.
10
11# Evaluate performance using the mean squared error and
12# the root of the mean squared error and r2
13
14# Making predictions for train set
15pred = lin_model.predict(X_train)
16
17# mse, rmse and r2
18print(
19 "train mse: {}".format(
20 int(mean_squared_error(np.exp(y_train), np.exp(pred)))
21 )
22)
23print(
24 "train rmse: {}".format(
25 int(mean_squared_error(np.exp(y_train), np.exp(pred), squared=False))
26 )
27)
28print("train r2: {}".format(r2_score(np.exp(y_train), np.exp(pred))))
29print()
30
31# Making predictions for test set
32pred = lin_model.predict(X_test)
33
34# mse, rmse and r2
35print(
36 "test mse: {}".format(
37 int(mean_squared_error(np.exp(y_test), np.exp(pred)))
38 )
39)
40print(
41 "test rmse: {}".format(
42 int(mean_squared_error(np.exp(y_test), np.exp(pred), squared=False))
43 )
44)
45print("test r2: {}".format(r2_score(np.exp(y_test), np.exp(pred))))
46print()
47
48print("Average house price: ", int(np.exp(y_train).median()))
train mse: 772198334
train rmse: 27788
train r2: 0.8763262128412839
test mse: 1077066272
test rmse: 32818
test r2: 0.8432700518729047
Average house price: 162999
1# Evaluate predictions wrt to the real sale price
2plt.scatter(y_test, lin_model.predict(X_test))
3plt.xlabel("True House Price")
4plt.ylabel("Predicted House Price")
5plt.title("Evaluation of Lasso Predictions")
Text(0.5, 1.0, 'Evaluation of Lasso Predictions')
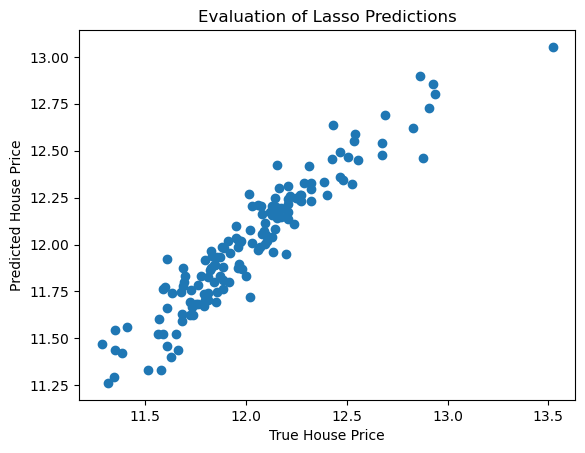
The model is doing a good job at estimating house prices.
1y_test.reset_index(drop=True)
| SalePrice | |
|---|---|
| 0 | 12.209188 |
| 1 | 11.798104 |
| 2 | 11.608236 |
| 3 | 12.165251 |
| 4 | 11.385092 |
| ... | ... |
| 141 | 11.884489 |
| 142 | 12.287653 |
| 143 | 11.921718 |
| 144 | 11.598727 |
| 145 | 12.017331 |
146 rows × 1 columns
1# Evaluating the distribution of the errors:
2# they should be fairly normally distributed
3y_test.reset_index(drop=True, inplace=True)
4
5preds = pd.Series(lin_model.predict(X_test))
6preds
0 12.175793
1 11.917238
2 11.662980
3 12.303104
4 11.423063
...
141 11.763792
142 12.329463
143 11.954652
144 11.772995
145 12.077226
Length: 146, dtype: float64
1# Evaluating the distribution of the errors:
2# they should be fairly normally distributed
3
4errors = y_test["SalePrice"] - preds
5errors.hist(bins=30)
6plt.show()
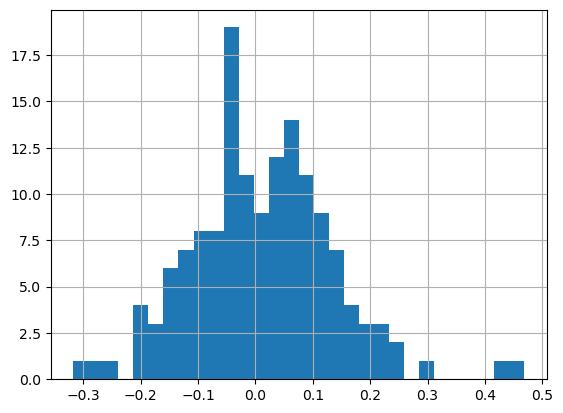
The distribution of the errors follows quite closely a gaussian distribution. That suggests that the model is doing a good job as well.
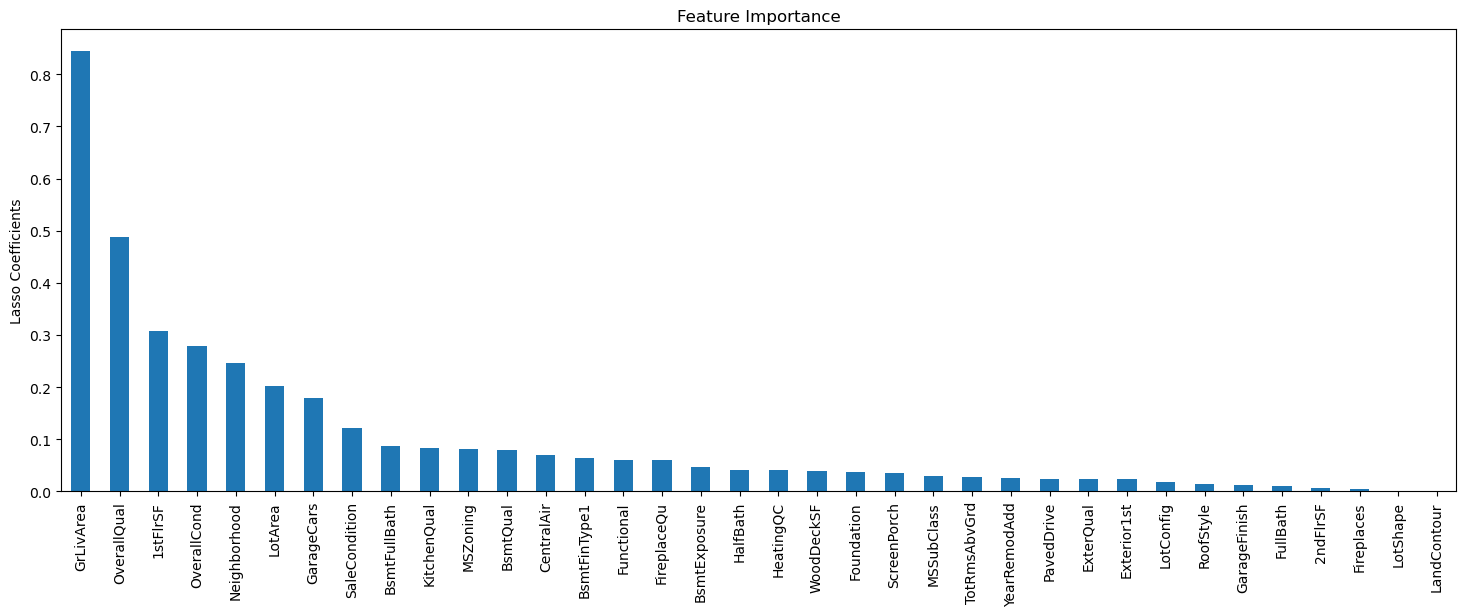
Feature importance#
1# Just for fun, feature importance
2importance = pd.Series(np.abs(lin_model.coef_.ravel()))
3importance.index = features
4importance.sort_values(inplace=True, ascending=False)
5importance.plot.bar(figsize=(18, 6))
6plt.ylabel("Lasso Coefficients")
7plt.title("Feature Importance")
Text(0.5, 1.0, 'Feature Importance')
Save the Model#
1# Save the model to be able to score new data
2
3joblib.dump(lin_model, f"{data_path}/linear_regression.joblib")
['./datasets/linear_regression.joblib']