

DBSCAN clustering#
DBSCAN is a density-based models: These models define clusters by their density in the data space. Areas with a high density of data points will become clusters, which are typically separated from one another by low-density areas.
The density-based spatial clustering of applications with noise (DBSCAN) algorithm groups together points that are close to each other (with many neighbors) and marks those points that are further away with no close neighbors as outliers.
Importing libraries and packages#
1# Mathematical operations and data manipulation
2import pandas as pd
3
4# Model
5from sklearn.cluster import DBSCAN
6from sklearn.metrics import silhouette_score
7from sklearn.metrics import calinski_harabasz_score
8
9# Plotting
10import matplotlib.pyplot as plt
11
12# Warnings
13import warnings
14
15warnings.filterwarnings("ignore")
16
17%matplotlib inline
Set paths#
1# Path to datasets directory
2data_path = "./datasets"
3# Path to assets directory (for saving results to)
4assets_path = "./assets"
Loading dataset#
1dataset = pd.read_csv(f"{data_path}/circles.csv")
Exploring dataset#
1# Shape of the dataset
2print("Shape of the dataset: ", dataset.shape)
3# Head
4dataset
Shape of the dataset: (1500, 2)
| 0 | 1 | |
|---|---|---|
| 0 | 0.393992 | -0.416376 |
| 1 | 0.528243 | -0.828242 |
| 2 | -0.740158 | 0.607730 |
| 3 | -0.971016 | 0.316821 |
| 4 | 0.018693 | -0.605288 |
| ... | ... | ... |
| 1495 | 0.085197 | -0.463028 |
| 1496 | 0.890820 | 0.003483 |
| 1497 | 0.223768 | -0.419122 |
| 1498 | 0.221189 | -0.510314 |
| 1499 | 0.544376 | 0.049358 |
1500 rows × 2 columns
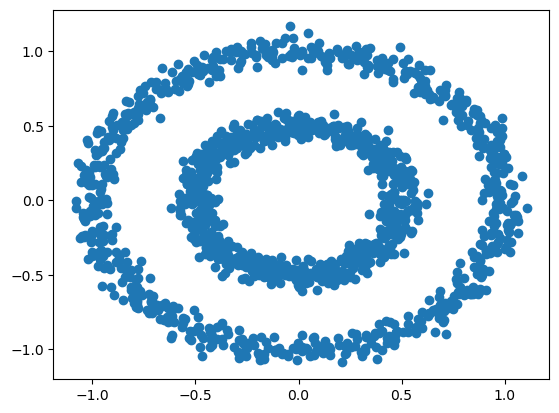
1plt.scatter(dataset.iloc[:, 0], dataset.iloc[:, 1])
2plt.show()
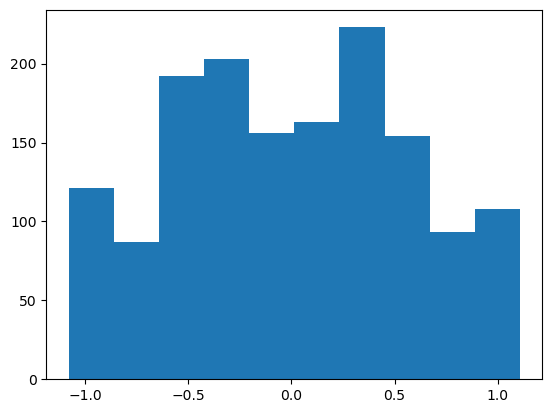
1# Using slicing to select the feature
2plt.hist(dataset.iloc[:, 0])
3plt.show()
DBSCAN#
1# Instantiate with an eps (the maximum distance that defines the
2# radius within which the algorithm searches for neighbors) of 0.1
3# - the value chosen after trying out all other possible values
4est_dbscan = DBSCAN(eps=0.1)
5# Fit the model to the data and assign a cluster to each data point
6pred_dbscan = est_dbscan.fit_predict(dataset)
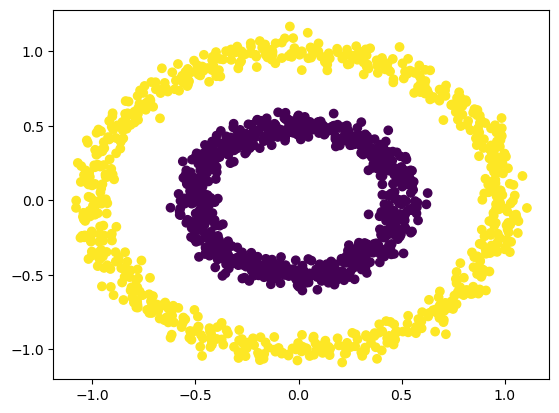
1# Plot the results from the clustering process
2plt.scatter(dataset.iloc[:, 0], dataset.iloc[:, 1], c=pred_dbscan)
3plt.savefig(f"{assets_path}/circles-dbscan.png", bbox_inches="tight")
4plt.show()
Metrics#
1# Silhouette
2dbscan_silhouette_score = silhouette_score(
3 dataset, pred_dbscan, metric="euclidean"
4)
5print(dbscan_silhouette_score)
0.11394082711912518
1# Calinski_harabasz
2dbscan_calinski_harabasz_score = calinski_harabasz_score(dataset, pred_dbscan)
3print(dbscan_calinski_harabasz_score)
0.0017164732936172393