Preprocessing#
Loading the data and performing some initial exploration on it to acquire some basic knowledge about the data, how the various features are distributed.
Importing libraries and packages#
1# Mathematical operations and data manipulation
2import pandas as pd
3
4# Plotting
5import seaborn as sns
6import matplotlib.pyplot as plt
7
8# Warnings
9import warnings
10
11warnings.filterwarnings("ignore")
12
13%matplotlib inline
Set paths#
1# Path to datasets directory
2data_path = "./datasets"
3# Path to assets directory (for saving results to)
4assets_path = "./assets"
Loading dataset#
1# load data
2dataset = pd.read_csv(f"{data_path}/hour.csv")
3dataset.head()
| instant | dteday | season | yr | mnth | hr | holiday | weekday | workingday | weathersit | temp | atemp | hum | windspeed | casual | registered | cnt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2011-01-01 | 1 | 0 | 1 | 0 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.81 | 0.0 | 3 | 13 | 16 |
| 1 | 2 | 2011-01-01 | 1 | 0 | 1 | 1 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 8 | 32 | 40 |
| 2 | 3 | 2011-01-01 | 1 | 0 | 1 | 2 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 5 | 27 | 32 |
| 3 | 4 | 2011-01-01 | 1 | 0 | 1 | 3 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 3 | 10 | 13 |
| 4 | 5 | 2011-01-01 | 1 | 0 | 1 | 4 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 0 | 1 | 1 |
Exploring dataset#
1# Shape and missing data
2print(f"Shape of data: {dataset.shape}")
3print(f"Number of missing values in the data: {dataset.isnull().sum().sum()}")
4
5# Statistics on the numerical columns
6dataset.describe().T
Shape of data: (17379, 17)
Number of missing values in the data: 0
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| instant | 17379.0 | 8690.000000 | 5017.029500 | 1.00 | 4345.5000 | 8690.0000 | 13034.5000 | 17379.0000 |
| season | 17379.0 | 2.501640 | 1.106918 | 1.00 | 2.0000 | 3.0000 | 3.0000 | 4.0000 |
| yr | 17379.0 | 0.502561 | 0.500008 | 0.00 | 0.0000 | 1.0000 | 1.0000 | 1.0000 |
| mnth | 17379.0 | 6.537775 | 3.438776 | 1.00 | 4.0000 | 7.0000 | 10.0000 | 12.0000 |
| hr | 17379.0 | 11.546752 | 6.914405 | 0.00 | 6.0000 | 12.0000 | 18.0000 | 23.0000 |
| holiday | 17379.0 | 0.028770 | 0.167165 | 0.00 | 0.0000 | 0.0000 | 0.0000 | 1.0000 |
| weekday | 17379.0 | 3.003683 | 2.005771 | 0.00 | 1.0000 | 3.0000 | 5.0000 | 6.0000 |
| workingday | 17379.0 | 0.682721 | 0.465431 | 0.00 | 0.0000 | 1.0000 | 1.0000 | 1.0000 |
| weathersit | 17379.0 | 1.425283 | 0.639357 | 1.00 | 1.0000 | 1.0000 | 2.0000 | 4.0000 |
| temp | 17379.0 | 0.496987 | 0.192556 | 0.02 | 0.3400 | 0.5000 | 0.6600 | 1.0000 |
| atemp | 17379.0 | 0.475775 | 0.171850 | 0.00 | 0.3333 | 0.4848 | 0.6212 | 1.0000 |
| hum | 17379.0 | 0.627229 | 0.192930 | 0.00 | 0.4800 | 0.6300 | 0.7800 | 1.0000 |
| windspeed | 17379.0 | 0.190098 | 0.122340 | 0.00 | 0.1045 | 0.1940 | 0.2537 | 0.8507 |
| casual | 17379.0 | 35.676218 | 49.305030 | 0.00 | 4.0000 | 17.0000 | 48.0000 | 367.0000 |
| registered | 17379.0 | 153.786869 | 151.357286 | 0.00 | 34.0000 | 115.0000 | 220.0000 | 886.0000 |
| cnt | 17379.0 | 189.463088 | 181.387599 | 1.00 | 40.0000 | 142.0000 | 281.0000 | 977.0000 |
Preprocessing temporal and weather features#
1def transform_seasons(data):
2 # Tranforming seasons
3 seasons_mapping = {1: "winter", 2: "spring", 3: "summer", 4: "fall"}
4 data["season"] = data["season"].apply(lambda x: seasons_mapping[x])
5 return data
6
7
8def transform_yr(data):
9 # Transforming yr
10 yr_mapping = {0: 2011, 1: 2012}
11 data["yr"] = data["yr"].apply(lambda x: yr_mapping[x])
12 return data
13
14
15def transform_weekday(data):
16 # Transforming weekday
17 weekday_mapping = {
18 0: "Sunday",
19 1: "Monday",
20 2: "Tuesday",
21 3: "Wednesday",
22 4: "Thursday",
23 5: "Friday",
24 6: "Saturday",
25 }
26 data["weekday"] = data["weekday"].apply(lambda x: weekday_mapping[x])
27 return data
28
29
30def transform_weathersit(data):
31 # Transforming weathersit
32 weather_mapping = {
33 1: "clear",
34 2: "cloudy",
35 3: "light_rain_snow",
36 4: "heavy_rain_snow",
37 }
38 data["weathersit"] = data["weathersit"].apply(lambda x: weather_mapping[x])
39 return data
40
41
42def transform_hum(data):
43 # Transorming humidity
44 data["hum"] = data["hum"] * 100
45 return data
46
47
48def transform_windspeed(data):
49 # Transorming windspeed
50 data["windspeed"] = data["windspeed"] * 67
51 return data
52
53
54def preprocess(data):
55 data = transform_seasons(data)
56 data = transform_yr(data)
57 data = transform_weekday(data)
58 data = transform_weathersit(data)
59 data = transform_hum(data)
60 data = transform_windspeed(data)
61 return data
62
63
64preprocessed_data = preprocess(dataset)
65preprocessed_data.to_csv(f"{data_path}/preprocessed_hour.csv", index=False)
1# Visualizing preprocessed columns
2cols = ["season", "yr", "weekday", "weathersit", "hum", "windspeed"]
3preprocessed_data[cols].sample(10, random_state=42)
| season | yr | weekday | weathersit | hum | windspeed | |
|---|---|---|---|---|---|---|
| 12830 | summer | 2012 | Saturday | clear | 27.0 | 12.9980 |
| 8688 | winter | 2012 | Monday | clear | 41.0 | 15.0013 |
| 7091 | fall | 2011 | Friday | clear | 66.0 | 19.0012 |
| 12230 | spring | 2012 | Tuesday | clear | 52.0 | 23.9994 |
| 431 | winter | 2011 | Thursday | clear | 56.0 | 26.0027 |
| 1086 | winter | 2011 | Friday | clear | 72.0 | 19.0012 |
| 11605 | spring | 2012 | Thursday | clear | 58.0 | 8.9981 |
| 7983 | fall | 2011 | Sunday | clear | 87.0 | 0.0000 |
| 10391 | winter | 2012 | Wednesday | clear | 68.0 | 12.9980 |
| 7046 | fall | 2011 | Wednesday | clear | 71.0 | 15.0013 |
Registered vs casual use analysis#
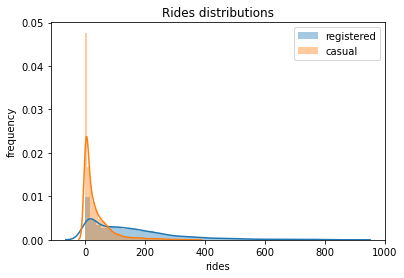
1# Plotting distributions of registered vs casual rides
2sns.distplot(preprocessed_data["registered"], label="registered")
3sns.distplot(preprocessed_data["casual"], label="casual")
4plt.legend()
5plt.xlabel("rides")
6plt.ylabel("frequency")
7plt.title("Rides distributions")
8plt.savefig(f"{assets_path}/rides_distributions.png", format="png")
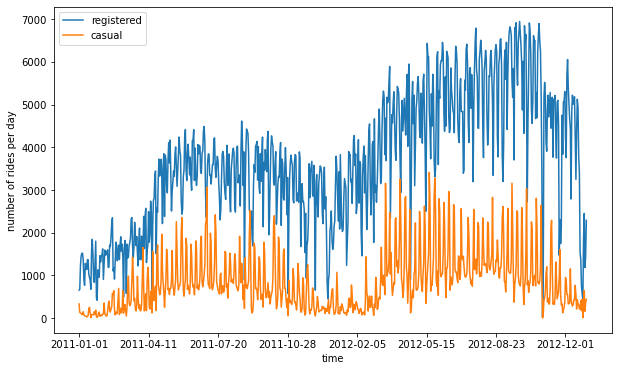
1# Plotting rides over time
2plot_data = preprocessed_data[["registered", "casual", "dteday"]]
3ax = plot_data.groupby("dteday").sum().plot(figsize=(10, 6))
4ax.set_xlabel("time")
5ax.set_ylabel("number of rides per day")
6
7plt.savefig(f"{assets_path}/rides_daily.png", format="png")
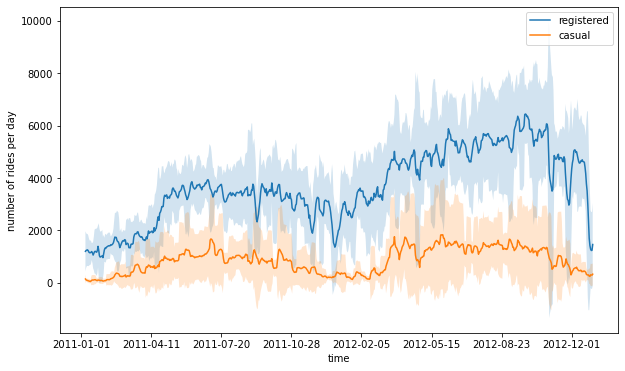
1# Creating a new dataframe for plotting columns, and obtaining number
2# of rides per day, by grouping over each day
3plot_data = preprocessed_data[["registered", "casual", "dteday"]]
4plot_data = plot_data.groupby("dteday").sum()
5
6# Defining window for computing the rolling mean and standard deviation
7window = 7
8rolling_means = plot_data.rolling(window).mean()
9rolling_deviations = plot_data.rolling(window).std()
10
11# Creating a plot of the series, where we first plot the series of
12# rolling means, then colouring the zone between the series of
13# rolling means +- 2 rolling standard deviations
14ax = rolling_means.plot(figsize=(10, 6))
15ax.fill_between(
16 rolling_means.index,
17 rolling_means["registered"] + 2 * rolling_deviations["registered"],
18 rolling_means["registered"] - 2 * rolling_deviations["registered"],
19 alpha=0.2,
20)
21ax.fill_between(
22 rolling_means.index,
23 rolling_means["casual"] + 2 * rolling_deviations["casual"],
24 rolling_means["casual"] - 2 * rolling_deviations["casual"],
25 alpha=0.2,
26)
27ax.set_xlabel("time")
28ax.set_ylabel("number of rides per day")
29plt.savefig(f"{assets_path}/rides_aggregated.png", format="png")
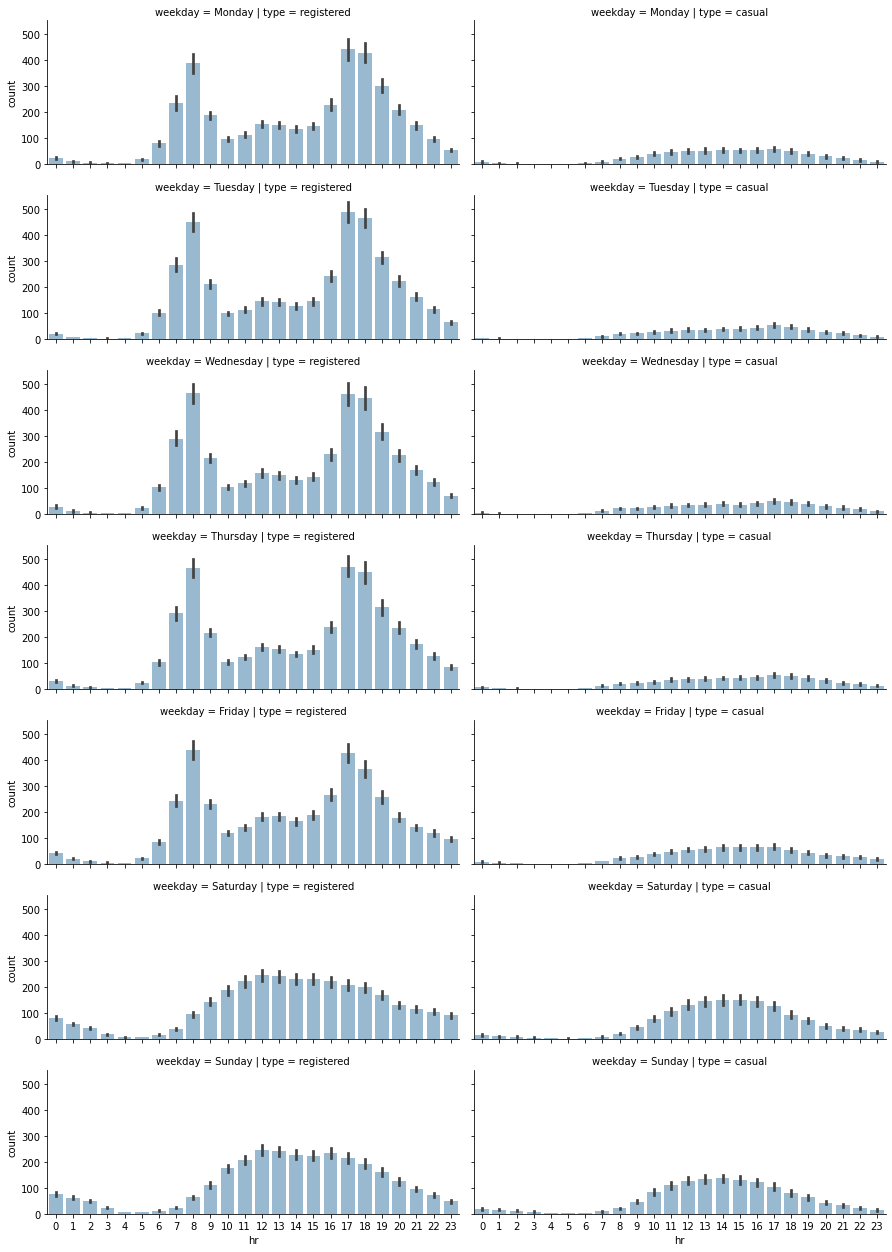
1# Selecting relevant columns
2plot_data = preprocessed_data[["hr", "weekday", "registered", "casual"]]
3
4# Transforming the data into a format, in number of entries are computed
5# as count, for each distinct hr, weekday and type (registered or casual)
6plot_data = plot_data.melt(
7 id_vars=["hr", "weekday"], var_name="type", value_name="count"
8)
9
10# Creating a FacetGrid object, in which a grid plot is produced.
11# As columns, we have the various days of the week, as rows, the different
12# types (registered and casual)
13grid = sns.FacetGrid(
14 plot_data,
15 row="weekday",
16 col="type",
17 height=2.5,
18 aspect=2.5,
19 row_order=[
20 "Monday",
21 "Tuesday",
22 "Wednesday",
23 "Thursday",
24 "Friday",
25 "Saturday",
26 "Sunday",
27 ],
28)
29
30# Populating the FacetGrid with the specific plots
31grid.map(sns.barplot, "hr", "count", alpha=0.5)
32grid.savefig(f"{assets_path}/weekday_hour_distributions.png", format="png")
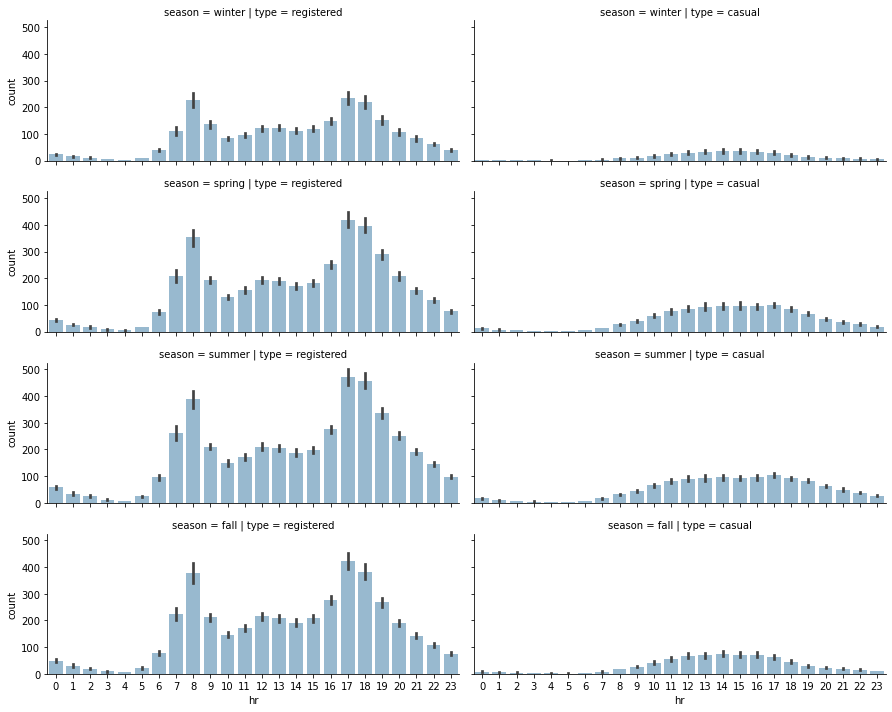
Analysing seasonal impact on rides#
1# Selecting subset of the data
2plot_data = preprocessed_data[["hr", "season", "registered", "casual"]]
3
4# Unpivoting data from wide to long format
5plot_data = plot_data.melt(
6 id_vars=["hr", "season"], var_name="type", value_name="count"
7)
8
9# Defining FacetGrid
10grid = sns.FacetGrid(
11 plot_data,
12 row="season",
13 col="type",
14 height=2.5,
15 aspect=2.5,
16 row_order=["winter", "spring", "summer", "fall"],
17)
18
19# Applying plotting function to each element in the grid
20grid.map(sns.barplot, "hr", "count", alpha=0.5)
21
22# Saving figure
23grid.savefig(f"{assets_path}/season_impact_a.png", format="png")
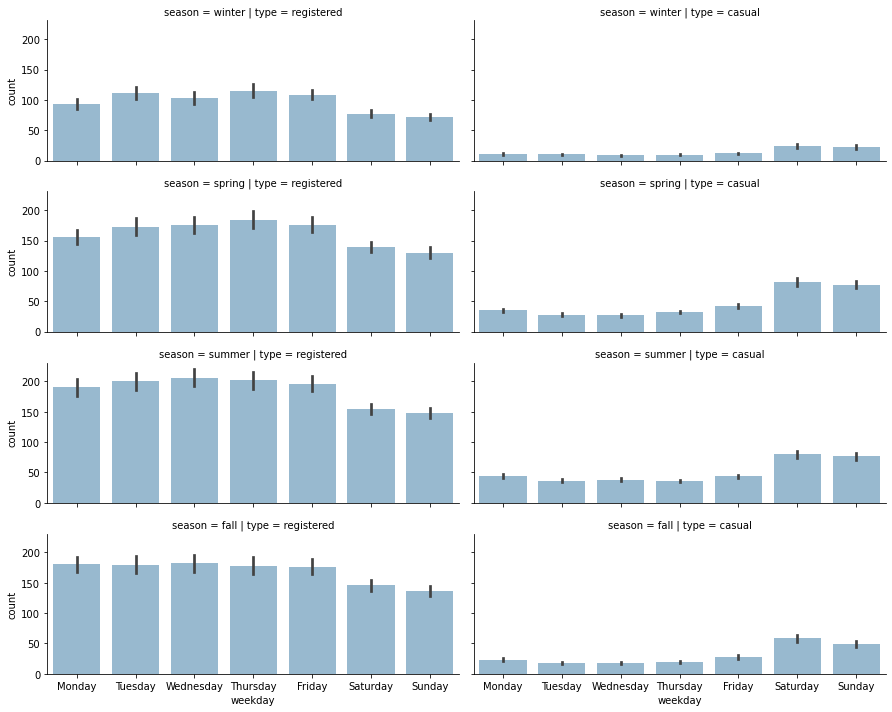
1plot_data = preprocessed_data[["weekday", "season", "registered", "casual"]]
2plot_data = plot_data.melt(
3 id_vars=["weekday", "season"], var_name="type", value_name="count"
4)
5
6grid = sns.FacetGrid(
7 plot_data,
8 row="season",
9 col="type",
10 height=2.5,
11 aspect=2.5,
12 row_order=["winter", "spring", "summer", "fall"],
13)
14grid.map(
15 sns.barplot,
16 "weekday",
17 "count",
18 alpha=0.5,
19 order=[
20 "Monday",
21 "Tuesday",
22 "Wednesday",
23 "Thursday",
24 "Friday",
25 "Saturday",
26 "Sunday",
27 ],
28)
29
30# Saving figure
31grid.savefig(f"{assets_path}/season_impact_b.png", format="png")